
Le Contexte :
En entreprise, les quantités de documents à trier peuvent parfois atteindre des proportions gigantesques. C’est le cas dans le domaine juridique où des milliers de documents nécessitent d’être interprétés avant d’être classés.
Jusqu’à maintenant, l’intelligence artificielle permettait de classer certains documents selon des critères relativement simples (langue, taille du document, format…). Cependant, ces modèles ne sont pas infaillibles. Ils ne peuvent pas catégoriser correctement des textes de structures similaires et dont les contenus se ressemblent. L’origine de leur incapacité à effectuer une tâche aussi cruciale provient de la difficulté à analyser proprement la sémantique des textes.
Les Solutions :
Afin de contourner le problème, il est possible d’entrainer les modèles avec un volume important de données. Ainsi, à l’aide des progrès du machine learning, les convergences statistiques par itérations (et oui … le ML ce n’est pas de la magie) permettent d’offrir des résultats très intéressants.
Un Nouveau Problème :
Cependant, ce genre de modèles deviennent rapidement obsolètes lorsqu’il s’agit d’ajouter de nouvelles catégories. Ils requièrent un réapprentissage parfois fastidieux, voire impossible !
Imaginez que vous deviez ajouter une nouvelle catégorie.
Contrairement aux commentaires clients sur les sites grand public, les documents juridiques sont dépourvus d’évaluations chiffrées ou étoilées.
Il vous faudra au moins 2000 exemples préclassés afin de créer un apprentissage optimum. Créer un jeu de données d’apprentissage dans un domaine aussi délicat que l’évaluation juridique devient un vrai travail de fourmis.
Dans ce contexte, la préparation d’un jeu de données compatible avec les techniques de classification automatique monopolisera vos experts pendant de longues heures. Peu de structures peuvent se permettre d’engager les coûts afférents.
Les Alternatives :
Enno Ai propose une alternative avec son nouveau modèle d’empreintes sémantiques. Celui-ci a démontré être capable de tenir compte de la sémantique des textes grâce à un faible apprentissage. De plus, il permet un traitement de texte plus proche de celui de la compréhension humaine.
Afin de démontrer ses qualités, nous l’avons mis à l’épreuve et comparé à deux modèles de traitement de texte :
→ la Similarité Cosinus : Nous avons utilisé la très bonne librairie spaCy (fr_core_news_lg). Comme de nombreux outils NLP, spaCy utilise la similarité cosinus. Elle permet d’établir la ressemblance entre les vocabulaires utilisés dans deux ensembles de textes différents. spaCy est une bibliothèque développée dans l’optique de fournir des solutions NLP aux entreprises. À ce jour, selon HG Insights, plus de 3000 entreprises ont recours à Spacy (1).
→ le TF-IDF (term frequency-inverse document frequency) : Nous avons utilisé l’excellente implémentation proposée par scikit-learn. Un grand nombre de chercheurs utilisent aujourd’hui cet algorithme (2) (3) pour l’analyse de textes. Il analyse la fréquence des mots clés des textes afin de déterminer s’ils partagent des thématiques communes.
De nos jours, ces deux technologies sont les plus utilisées et reposent sur des algorithmes révélés il y a 20 (4) ou 50 ans (5). Vous les retrouverez dans tous les moteurs d’analyses NLP de Google à Amazon en passant par Microsoft.
Les Modalités de notre Test :
Dans ce test, nous avons cherché à comparer des ensembles de textes correspondant à 6 thématiques présentes dans le milieu juridique (travail, logement, transport, santé, règlement et procédure judiciaire).
Pour chacun de ces sujets, deux ensembles de textes sont créés à partir de phrases issues de documents juridiques officiels (6). Chaque ensemble de texte est constitué de 5 à 6 phrases en moyenne, chacune provenant d’un document différent.
Pour une catégorie donnée, le score final correspond à la différence de deux valeurs. Le score de comparaison des deux textes de cette catégorie auquel nous soustrayons la moyenne des scores issus des comparaisons entre ces deux textes et ceux des autres catégories.
Les Résultats :
Dans l’ensemble, le modèle Enno Ai obtient de meilleurs résultats que les modèles de spaCy et TF-IDF (cf Figure 1). Cependant le modèle TF-IDF présente un score plus élevé pour la catégorie ‘travail‘.
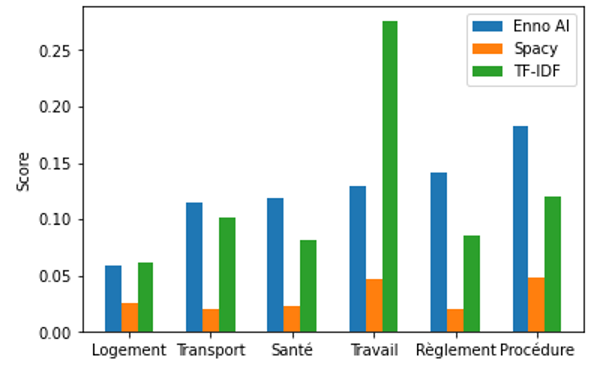
Cette différence peut s’expliquer par la spécificité de la catégorie ‘travail‘. En effet, elle possède un lexique spécifique récurrent composé de termes comme ‘travail’, ‘salarié’, ‘emploi’, ‘entreprise’.
Les autres catégories ne possèdent pas de champ lexical aussi prononcé. Elles sont ainsi plus difficiles à distinguer pour l’algorithme TF-IDF. C’est pourquoi ce modèle performe moins bien sur d’autres catégories telles que ‘transport‘ ou ‘règlement‘. En conclusion, ce modèle ne peut pas distinguer proprement des textes nuancés comprenant une multitude de concepts.
Nous avons ensuite fait varier le nombre de phrases utilisées par ensemble de texte.
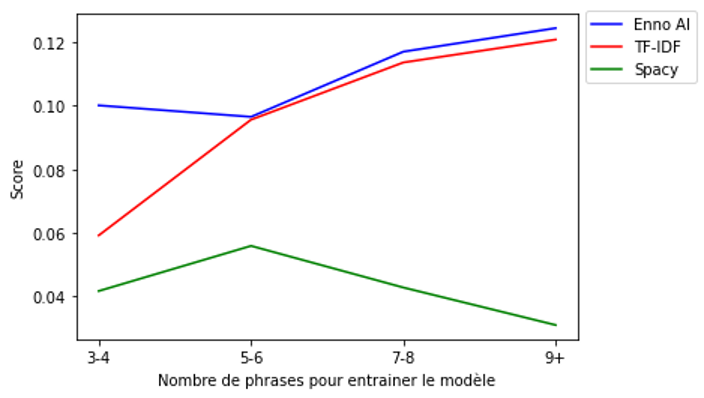
Les scores obtenus augmentent plus pour le modèle Enno Ai que pour le modèle TF-IDF (cf Figure 2). Quant à la similitude cosinus, elle s’effondre. De plus notre modèle conserve un écart type faible contrairement au modèle TF-IDF ou spaCy.
Conclusion :
Le modèle Enno Ai obtient de meilleurs résultats que des modèles utilisés sur le marché. Cette différence croît lorsqu’un très faible volume de données est disponible.
Notre moteur d’analyse peut ainsi être rapidement personnalisé en fonction des besoins d’une entreprise ou d’une expertise. Il peut être aussi bien utilisé dans le domaine du juridique que dans le votre.
Vous souhaitez tester la différence ?
(1) https://discovery.hgdata.com/product/spacy
(2) https://www.researchgate.net/publication/326425709_Text_Mining_Use_of_TF-IDF_to_Examine_the_Relevance_of_Words_to_Documents
(3) https://hcis-journal.springeropen.com/articles/10.1186/s13673-019-0192-7
(4) Cosine Similarity : Modern Information Retrieval: A Brief Overview
(5) TF-IDF: A statistical interpretation of term specificity and its application in retrieval
(6) https://www.service-public.fr/particuliers/